Student Projects
Design of a 32-bit, Three-way Pipeline Superscalar VeriSimpleV Processor
Project Video
Team Members

Team Members:
吴哲泓 Zhehong Wu 林意朋 Yipeng Lin 李瑞浦 Ruipu Li 徐牧辰 Muchen Xu 叶天晨 Tianchen Ye 王煜恒 Yuheng Wang
Instructors:
Xinfei Guo
Project Description
-
Problem
Modern processors arehighly paralleled to improve performance. However, the paralleled processorscan encounter issues like forwarding, ordering, structural hazard, etc. Thisproject expends a 32-bit, one-way VeriSimpleV processor to a three-waysuperscalar processor.
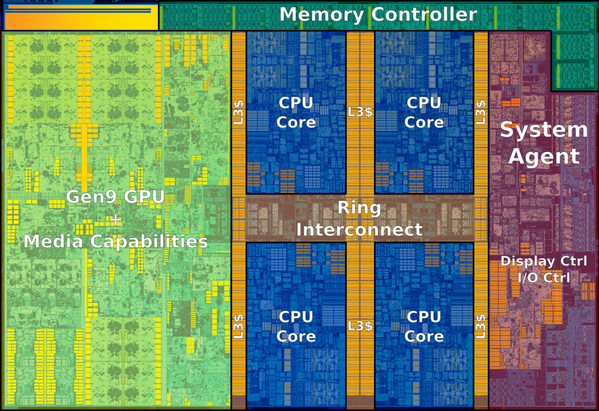
Fig. 1 Die map of Intel “Skylake”Quad-core processor [1]
-
Concept Generation
Issues caused by paralleled pipeline are firstly identified asfollowing.
•Data hazard:Data hazard includes forwarding and interdependency. Forwarding iscaused by an instruction needs results from later stages. Interdependency iswhen instructions between three paralleled pipeline in the same stage havedependencies.
•Structural hazard:Due to limited width of memory port, reading instructions andreading or writing data cannot happen at the same time.
•Control hazard:When branch is happening, other instructions processed in thepipeline that should not be processed after the branch need to be flushed.
•Ordering:Instructions fed into the three-way superscalar pipeline need to bein-order to prevent wrong memory and register write order.
-
Design Description
The basic VeriSimpleV processor’s IO ports,processing units, memory module IO, and register file IO are tripled to make ita three-way superscalar processor. The following systems are implemented tosolve the above design challenges.
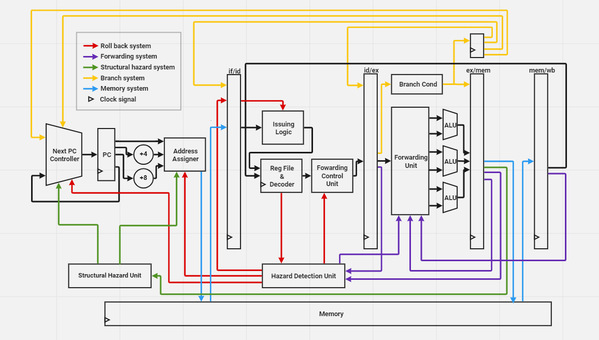
Fig.2 Three-way superscalardesign
•Rollback system:
Rollback system takes care of interdependency by storinginstructions after the instruction that causes interdependency in ID stage andreissuing those instructions in the next cycle together with new instructionsfetched from IF stage. The rollback signal will inform next PC controller andaddress assigner to avoid lines that will be replaced by stored instructions.
•Forwarding system:
Detection unit firstly detect data hazard within previous twocycles then activate forwarding path from MEM stage and WB stage to addressdependency issue.
•Ordering system:
Address assigner reorder detect each instruction fetched bycomparing their PC value. Issue logic combined the in-order stored instructionsand the in-order instructions from IF stage.
•Branch system:
The pipeline always predict branch will not happen. When predictionis wrong, branch system will flush instructions after the branch instruction that are processed in pipelines.
•Structural hazard system:Structural hazard unit detects number of ports occupied by memorydata read and write. Then it assign the left available port to fetchinstructions. As instructions are 32-bit and the data read and write are64-bit, address assigner can fetch two instructions even if two memory port areoccupied if PC is the lower half of the fetched instructions.
-
Validation
The design is implemented using System Verilog and is validatedwith behavioral simulation in Vivado 2021.2. Programs arecompiled to binary code as testbenches for the designs. The clock cycle perinstruction (CPI) is calculated to indicate pipeline performance and iscompared with two-way superscalar, pipeline with forwarding paths, and basicpipeline.
-
Modeling and Analysis
The performance of a superscalar pipeline is much better compared to a scalar pipeline. However, the performance of a three-way superscalar is slightly better than a dual pipeline, and we figured out that our branch prediction method could be improved, as a certain number of cycles would be wasted when a branch is mispredicted no matter how many ways a superscalar has.
Fig.3 CPI comparison acrossimplementations
-
Conclusion
Three-way superscalar can significantly improve the performancecomparing to two-way superscalar and one-way implementation. The performanceimproves slower with more ways.
-
Acknowledgement
Faculty Advisor: Xinfei Guo from UM-SJTU JointInstitute
-
Reference
[1]https://en.wikichip.org/wiki/intel/microarchitectures/skylake_(client)