Student Projects
VM450
Evaluation and Improvement of Vehicle Energy Optimization System in Open-ended Simulation Environment
Project Video
Team Members

Team Members:
Fang, Han; Xu, Zeheng; Xu, Yihang; Lu, Dongyun Zhang, Siyuan
Instructors:
Chengbin Ma
Project Description
-
Problem
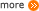
With the rise of unmanned driving, the energy consumption of unmanned driving vehicles becomes the next focus of the industry. Companies like Newrizon try to use algorithms for driving assistants to optimize energy consumption. However, such optimization tests in roads take much time and money. So the implementation of energy consumption in a simulation platform will be a good approach.

Figure 1: Newrizon Vehicle Company[1]
-
Concept Generation
Among calibration, imitation learning, and Reinforcement, we choose Deep Deterministic Policy Gradient as the optimization method. And Metadrive is chosen as the better simulation platform than Carla. DDPG is a structure in reinforcement learning that enables the system to carry out optimizations in the process of seeking a higher reward. Metadrive is a simulation platform that is able to generate infinite maps with various traffic and environmental settings with high efficiency.
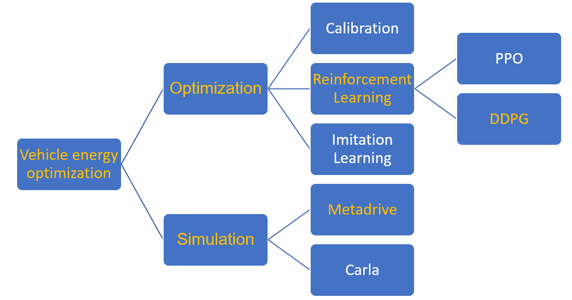
Figure 2: Method & Platform Selection
-
Design Description
Metadrive generates an environment that allows the agent to explore, handling the physical interactions between the vehicle and map. The agent will generate action based on the observation and interaction with the environment, receiving feedback or rewards. Standing on the DDPG algorithm, experiences by exploring and exploiting the possible outcomes of different actions. The back and forth interactions form a loop, the training process, which will the agent is able to learn from the not terminate until convergence.
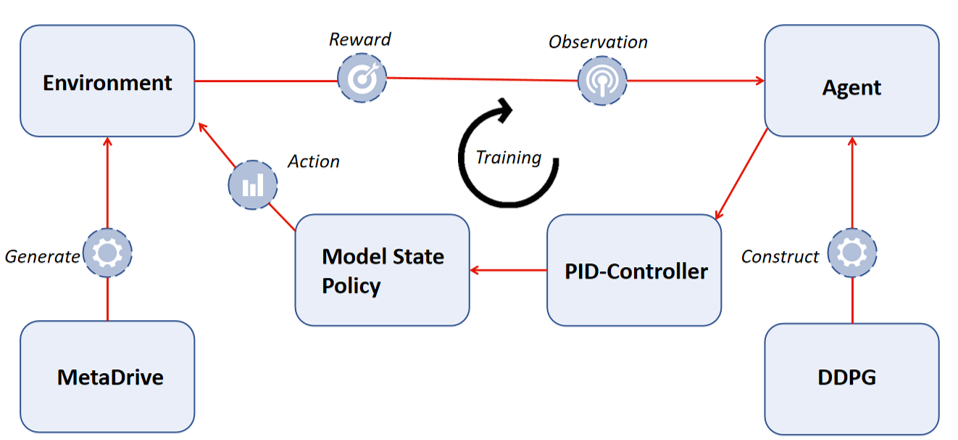
Figure 3: Concept diagram
-
Validation
Validation Process:
For the energy optimization rate, the energy consumption of idem policy and DDPG agent was compared. For the energy consumption, a vehicle energy estimation model[2], which considers the friction, wind drag, acceleration, and steering process was applied.
For the response time and process delay, the average of multiple time slots in one process was calculated.
Some other specifications can also be verified using easy experiments.
Validation Results:
According to the validation part, most specifications can be met.
Energy optimization rate>=5%
Response time<=0.02s
Process delay<=0.016s
Brake distance at 50km/h<=21m
Developing time<=200h
Cost<=$1500
Average speed>=81km/h
means to be further determined and subject to change.
-
Modeling and Analysis
For each step the agent interacts with the environment, a reward will be given, which is a weighted sum of stability, speed, and energy consumption. As can be seen in the figure below, at the beginning of the training, the agent gets a high reward occasionally. However, as the training goes on, the agent can constantly get a higher reward, which means that the agent is learning to behave better. A peak even occurred at the later training process, meaning that the vehicle reaches the terminal state successfully.
Figure 4: Reward with training step
-
Conclusion
Reinforcement learning can be used for optimizing the energy consumption in the simulation platform. A well-designed reward is essential to train successfully. And also, the energy optimization rate and the response time are vital to evaluate the optimizing method.
-
Acknowledgement
Faculty Advisor: Chengbin Ma from UM-SJTU Joint Institute
Sponsor:Binjian Xin from Newrizon
-
Reference
[1] Newrizon vehicle company.https://www.newrizon.com/. October 24, 2021.
[2] Charles Mendler. “Equations for Estimating and Optimizing the Fuel Economy of Future Automobiles”. In: (1993).