Problem Statement
The substantial memory and computational requirements of Large language models (LLMs) pose significant deployment challenges. Model compression, particularly quantization, is crucial for efficient LLM inference, offering size reduction with minimal performance loss. The current landscape of quantization presents various methods, each with unique trade-offs between hardware efficiency and model performance. This diversity complicates the selection of optimal methods and models for different platforms.
Concept Generation
Quantization, as a multifaceted model-level optimization method, requires comprehensive consideration of various factors in the context of SW-HW codesign for efficient LLM inferencing:
quantization hyperparameters: precision, granularity…
whether to quantize activation values and KV cache.
These considerations must be made in conjunction with other methods spanning from data-level to system-level.
Design Description
Our experimental design consists of systematical tests and evaluations of various quantization and optimization strategies across different hardware condition. By exploring the Pareto Frontiers(sets of optimal solutions where no criterion can be improved without compromising another), we identify balanced deployment strategies that maintain high model performance while minimizing the memory and compute consumption.
Modeling and Analysis
We conducted a detailed analysis across various frameworks and quantization strategies.
Model performance was evaluated with lm-eval[2] using MMLU accuracy and WikiText2 perplexity.
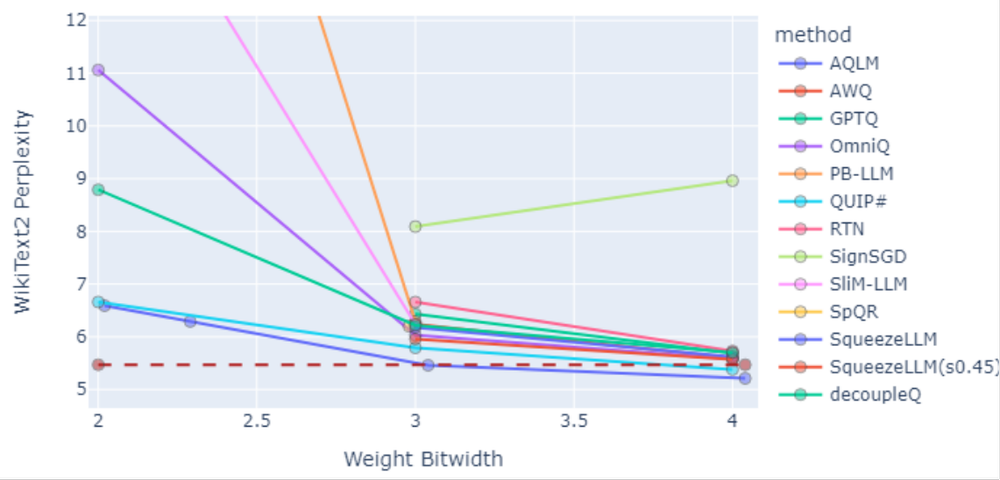
As illustrated in Fig.3, recent methods are pushing the boundaries of low-bit quantization while minimizing performance loss.
Hardware efficiency was assessed with llmuses[3] based on memory and time overhead.
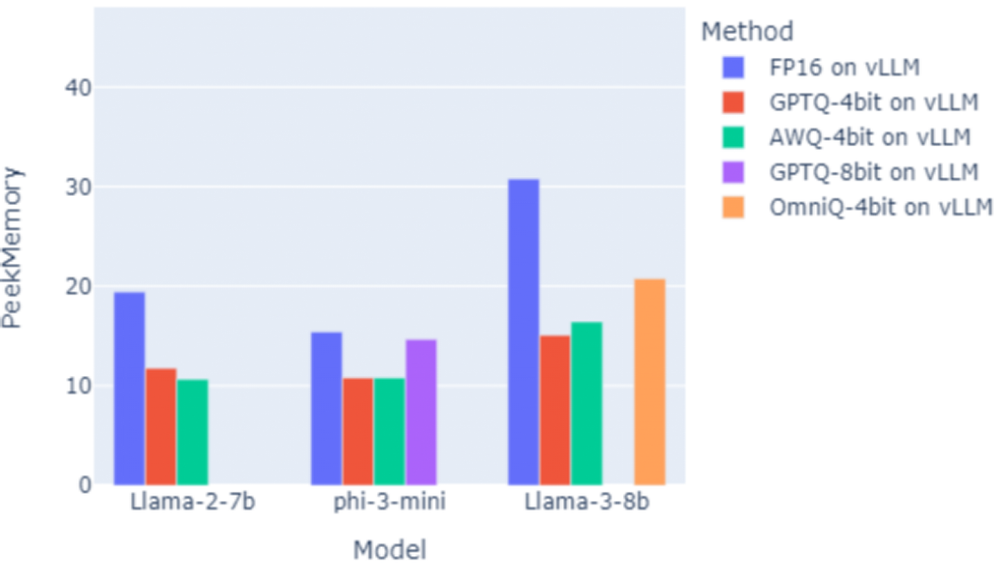
Quantization significantly reduces peak memory overhead, enabling them to fit in edge computing devices, as shown in Fig.4
Validation
Validation Process:
We further evaluated a case pick from Pareto Frontier, phi-3-mini quantized by AWQ (W4A16g128) on vLLM [4].
Validation Results:
Peek Memory of 10.81GB, even able to be deployed on Jetson Orin.
Accuracy maintained on bar with GPT3.5 after 4-bit quantization.
Conclusion
Our study highlights the effectiveness of various quantization strategies in optimizing LLMs for diverse hardware platforms. By systematically evaluating model performance and hardware utilization, we identified balanced solutions.
Acknowledgement
Prof. GUO Xinfei, PhD(c). XU Ruge from UM-SJTU Joint Institute
Reference
[1] arXiv:2402.09748
[2] github.com/EleutherAI/lm-evaluation-harness
[3] github.com/modelscope/eval-scope
[4] github.com/vllm-project/vllm